
In the last decade, machine learning, recognized as a subset of artificial intelligence, has gained prominence for its capacity to discern significant patterns from training data. This advancement has extended to predicting the perceptual patterns in non-native language speech, a domain often guided by the implicit assumption that phonetic similarities between one’s first language (L1) and second language (L2) can influence L2 sound perception.
Notably, a research paper published in the esteemed scientific journal Scientific Reports, ranked as the 5th most cited journal globally and affiliated with the renowned Nature journal, authored by Dr George Georgiou, an Assistant Professor of Linguistics at the University of Nicosia and Director of the Phonetic Lab, endeavors to evaluate the alignment between machine-generated predictions and human speech perception. The focus of the study is to assess the predictive capabilities of three machine learning algorithms: Linear Discriminant Analysis (LDA), Decision Tree (C5.0), and Neural Network (NNET) in classifying speakers’ L1 vowels in terms of L2 categories. The effectiveness of this classification holds significant implications for achieving enhanced communicative competence by identifying and distinguishing non-native language sounds.
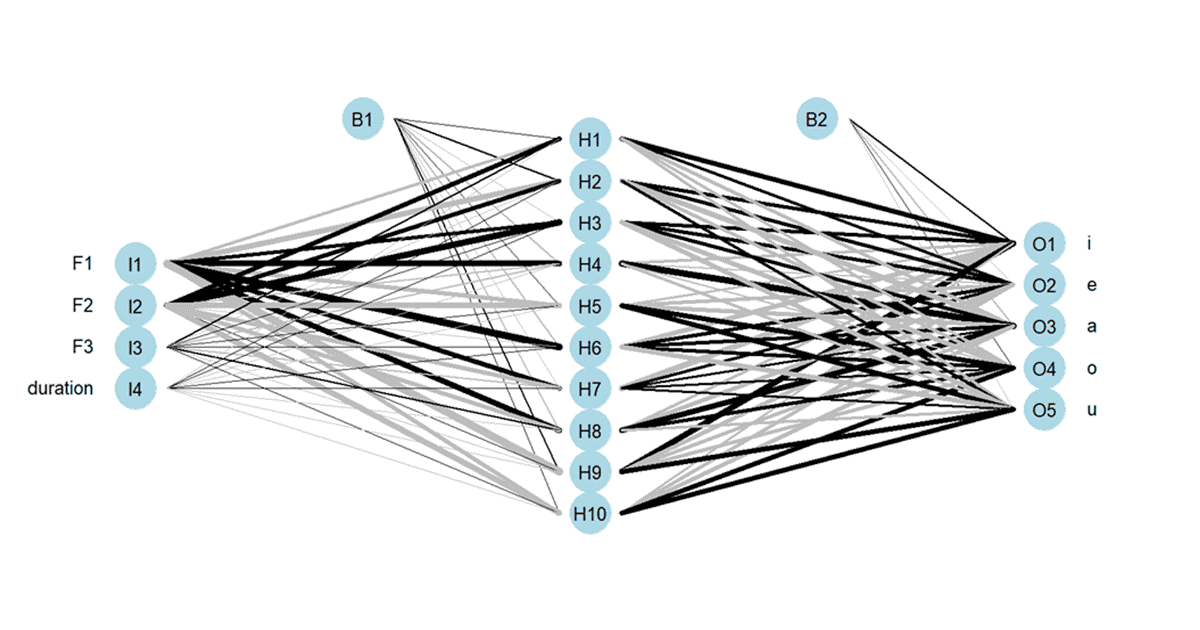
The machine learning models were trained using the first three formants and the duration of Cypriot Greek vowels (L1) and were then subjected to the same acoustic features extracted from English vowels (L2). To gauge the accuracy of these algorithms, adult native speakers of Cypriot Greek, who spoke English as their L2, participated in a psychoacoustic vowel classification test. The results unveiled that the neural network demonstrated superior performance in predictions, followed closely by the discriminant analysis. In contrast, the decision tree algorithm fell short of anticipated performance levels. The neural network’s advantage lay in its ability to employ deep learning techniques, utilizing multi-layered neural structures capable of capturing abstract and high-level features, thus outperforming simpler algorithms like discriminant analysis and the decision tree. The neural network’s adaptability and flexibility further contributed to its superior performance, allowing it to adjust internal parameters to better align with underlying dataset patterns.
Furthermore, the research acknowledged that the complexities of human speech perception often defy linear boundaries in n-dimensional spaces, making the neural network’s performance, which excels at understanding intricate, non-linear relationships, somewhat expected. Notably, discriminant analysis closely approached the neural network’s performance, indicating that the relationship between L1 and L2 categories might predominantly entail non-linear attributes, thus explaining the two algorithms’ similar accuracy. On the other hand, the decision tree’s suboptimal performance could be attributed to its susceptibility to overfitting, especially in complex tree structures or with small datasets. It may also be linked to its inability to handle continuous variables, such as formant frequencies and vowel duration, as employed in this study.
The significance of these findings lies in their potential to inform speech perception studies, particularly in predicting L2 sound classifications. These results highlight the applicability of advanced algorithms like neural networks in estimating L2 sound classifications and shaping research hypotheses. Additionally, while cognitive models and machine learning approaches have distinct goals and methodologies, the latter can offer valuable insights into the mechanics of speech perception, including the role of auditory cues. This, in turn, can be beneficial for educational purposes, as educators can choose algorithms that offer optimal predictive performance to tailor instructional tools for learners with diverse L1 backgrounds and challenges in L2 sound perception. Lastly, the findings hold promise for enhancing automatic speech recognition systems, enabling them to detect subtle phonetic distinctions and adapt to variations in speech sounds, particularly as influenced by the unique phonetic characteristics of non-native speakers.
Source: University of Nicosia | News (https://shorturl.at/apH06)